The upcoming Tasks API defines an interface for interacting with objects that are expected to run outside of the typical HTTP request/response cycle, like sending emails. The API includes a TaskResult class for obtaining task progress and return values.
Interestingly, Django deliberately avoids adding support for task runtimes; Django 6.0 defines a common API for queuing tasks and obtaining results, but does not prescribe how tasks should actually be executed. Instead, it allows future task execution providers to “plug in” via the familiar BACKEND setting.
Reading the Django Enhancement proposal (DEP 14), the main motivation for this is clear: "[…] the ecosystem is filled with incredibly popular frameworks, all of which interact with Django in slightly different ways […]"
It’s difficult to discuss this feature without celery coming to mind… It’s the de facto standard for defining and actually running tasks for Django projects, as far as I’m aware. I’ve used Celery extensively (it’s part of my go-to tooling for Django projects), and I’m curious to see how this standardized interface will be adopted by them, if at all.
I’d expect either the celery project itself or someone else to write a celery-compatible Task backend (or wrapper) in the near future, although a quick scan of the project’s issues page yields no results…
2. Template Partials
Built-in support for template partials is also coming in Django 6.0. I think this improvement to the core templates component is particularly welcome given the increasing adoption of htmx in Django projects, as shown in the recently published 2025 Django Developer Survey results.
{%partialdefuser_card%} <div class="card">
<h3>{{user.username}}</h3>
<p>{{user.email}}</p>
</div>
{%endpartialdef%}<!-- Reuse the partial using the partial name and provide context -->
{%partialuser_carduser=current_user%}
The ability to directly access named partials is likely to become the best-practice approach when it comes to working with htmx-style “respond with an HTML snippet” requests.
Django 6.0 also includes built-in Content Security Policy support. For a second time now, this is essentially “vendoring-in” a popular third-party package, in this case django-csp. I tend to view this pattern positively, as it further reinforces Django’s “batteries-included” philosophy.
“CSP” is a browser security standard that helps prevent cross-site scripting (XSS) and other code injection attacks by controlling which resources (scripts, images, etc.) can be loaded and executed on your web pages.
With Django 6.0, you can configure CSP policies directly in your settings:
You’d also need to make sure to set up the proper middleware, see the how-to guide for more details.
Defining and maintaining a CSP is an important (and in my experience, often overlooked) part of a project’s production readiness. Setting up a proper CSP helps protect against injection attacks, which rank #5 in this year’s OWASP Top 10.
How to Use These Features Today
You can opt in to start testing these features today. The latest pre-release for the 6.0 branch is Django 6.0 beta 1, tagged as 6.0b1.
There are a bunch of other features and improvements coming besides the ones highlighted above, so be sure to check out the release docs if you’re interested.
Django 6.0 is set to be publicly released on December 3rd, 2025.
In this post, I’d like to share my research and process for getting this all to work.
tl;dr - click to expand (spoilers)
Patched the News Channel’s hardcoded Nintendo URL to point to an S3 storage bucket using Go and wadlib to extract the necessary binary file and edit it in-memory
Modified WiiLink’s open-source news file generator to add “El Nuevo Día” as a news source
Set up AWS Lambda + EventBridge to regenerate the necessary news binary files hourly
The News Channel debuted in North America on January 26, 2007, a little over two months after the Wii’s launch. Since that date, it mostly came pre-installed with Wii consoles and was a novel way to read news from all over the world. Together with other “utility” channels like the Forecast Channel, it tried to position the Wii as more than just a gaming console.
Check out a video recording of the service from right before it was discontinued on June 27th, 2013:
How the News Channel fetches content
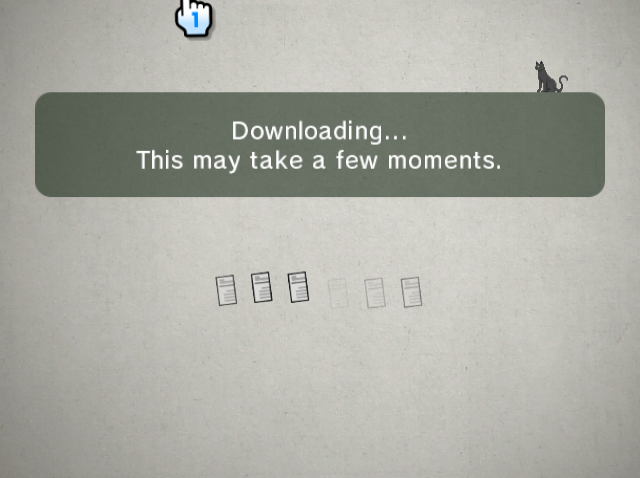
Before we can consider displaying custom news on it, we have to figure out how the News Channel actually fetches content. We know that it must have fetched news somehow since it displays a “Downloading…” splash screen on startup.
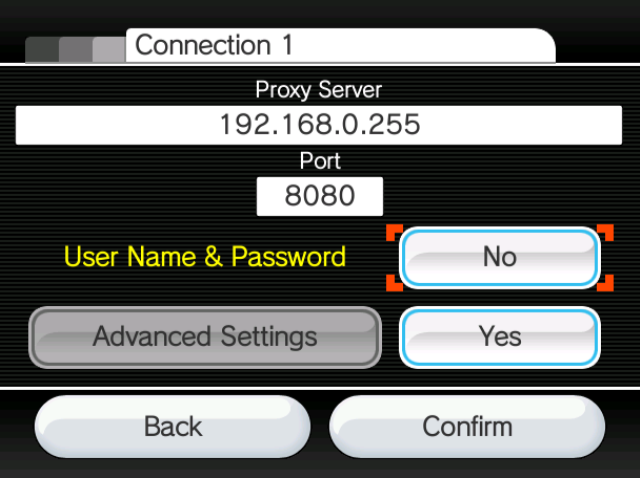
Luckily for us, the Wii natively supports proxying via its internet connection configuration settings! Meaning we can set up something like mitmproxy on a local machine and observe its HTTP behavior.
We can start mitmproxy’s web interface for a more screenshot-friendly UI:
mitmweb --listen-port 8080
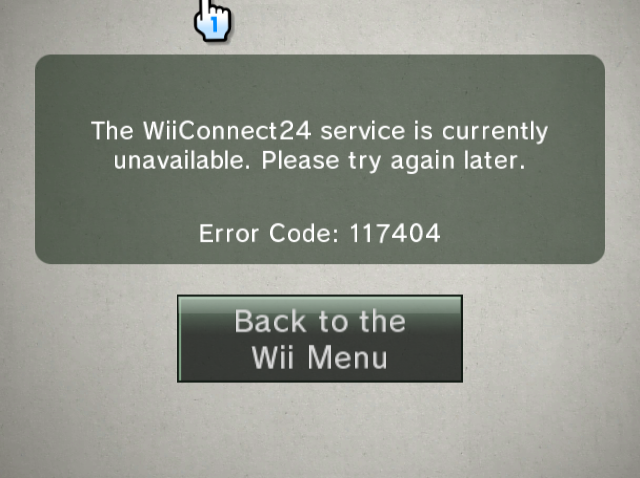
If we run a man-in-the-middle proxy for the News Channel on an unmodified Wii, we will observe that, on channel startup, it attempts to obtain a news.bin.00 file from http://news.wapp.wii.com/v2/1/049/news.bin.00 via a plain HTTP request.
URL path explainer (we’ll see later how I found this out):
1 corresponds to “English” as the configured console language. See conf.h in devkitPro (the Wii homebrew community’s de-facto development toolchain) for the possible values.
049 is the Wii’s country code for “United States”. Check out the full list of Wii country codes on wiibrew.org.
Once it fails to fetch this file, the News Channel displays an error. What might these binary files be? In any case, seeing the Wii perform an HTTP request to fetch news data is a good sign for us. It means we might be able to serve our own data.
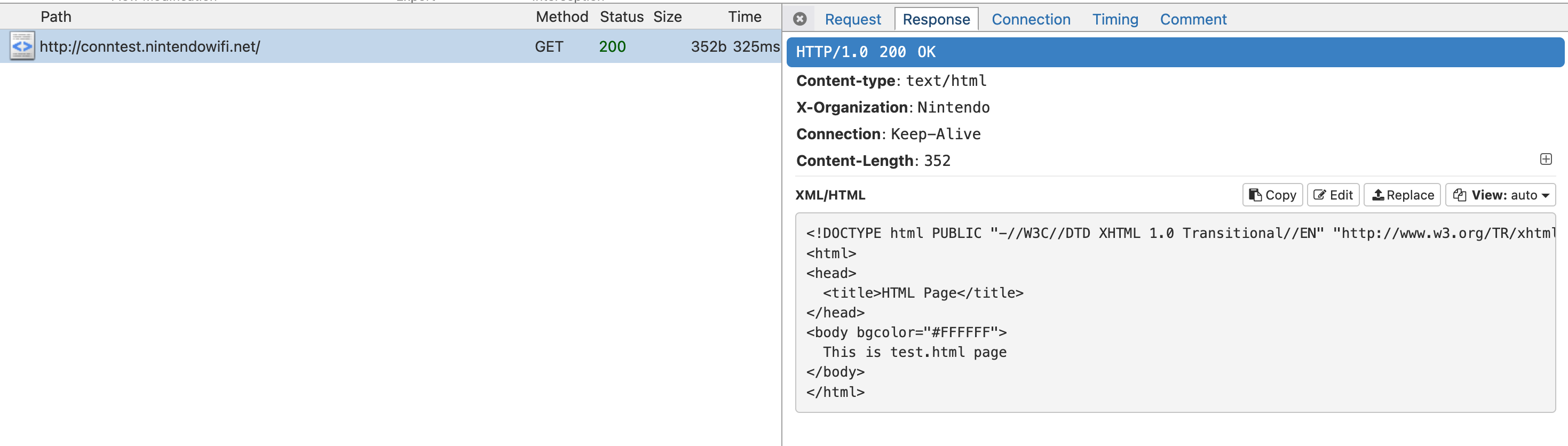
By the way, if you run an internet connection test after configuring the proxy settings correctly, you’ll spot the Wii performing an HTTP request to http://conntest.nintendowifi.net. Turns out, this page is actually still online (see for yourself!)
The Wii’s internet connection test still passes to this day without any modification required. Thanks, Nintendo!
Enter WiiLink: the homebrew community keeping Wii online services alive
Up to this point, this is how we would expect the Wii would behave if you were running a stock console. More than 12 years ago, Nintendo discontinued support for the online functionality of the News Channel.
But as expected for a beloved retro console, community efforts have sprung up to try and preserve the previously existing functionality and allow users to continue enjoying these systems well past their intended expiration date. These sorts of unofficial software for gaming consoles are commonly referred to as “homebrew”.
Importantly for this project, the WiiLink team maintains servers and develops software that allows us to experience the Wii’s online connectivity features even today.
By the way, if you’re curious about how to get started with Wii console homebrew, check out https://wii.hacks.guide.
Thanks to WiiLink, we can revive the News Channel and browse up-to-date news! Just not the local news, which is our real goal.
How WiiLink patches the News Channel
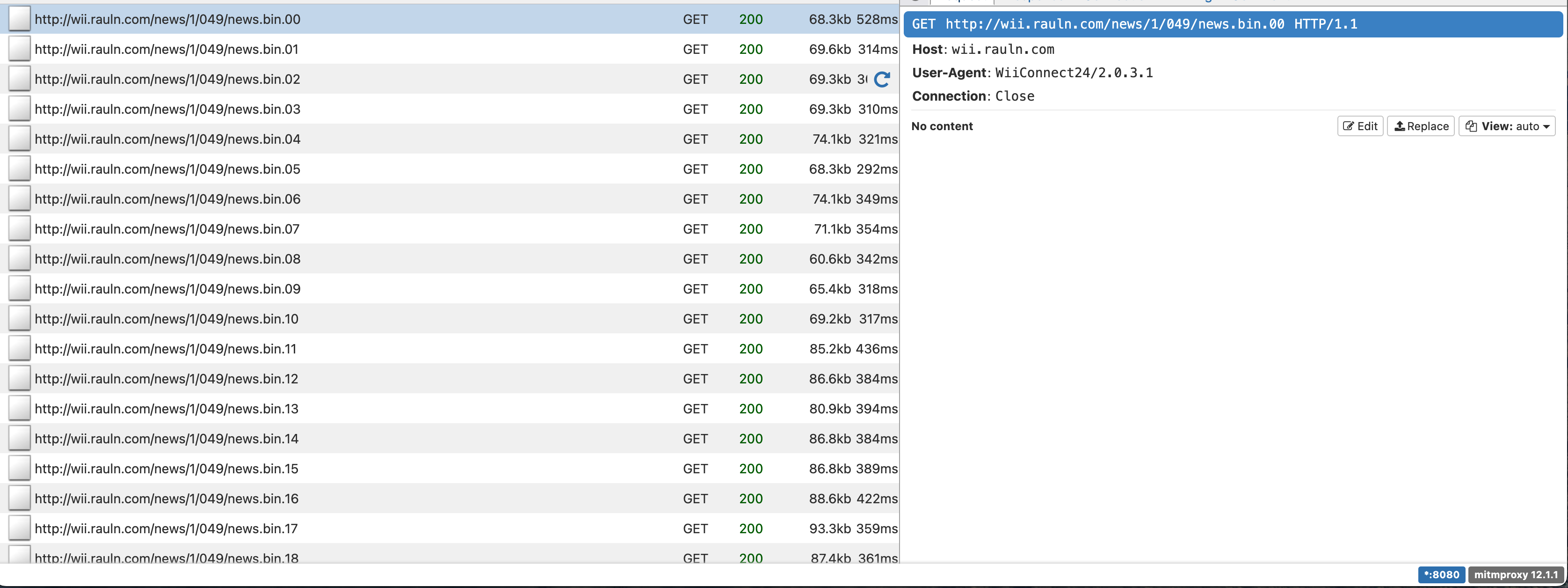
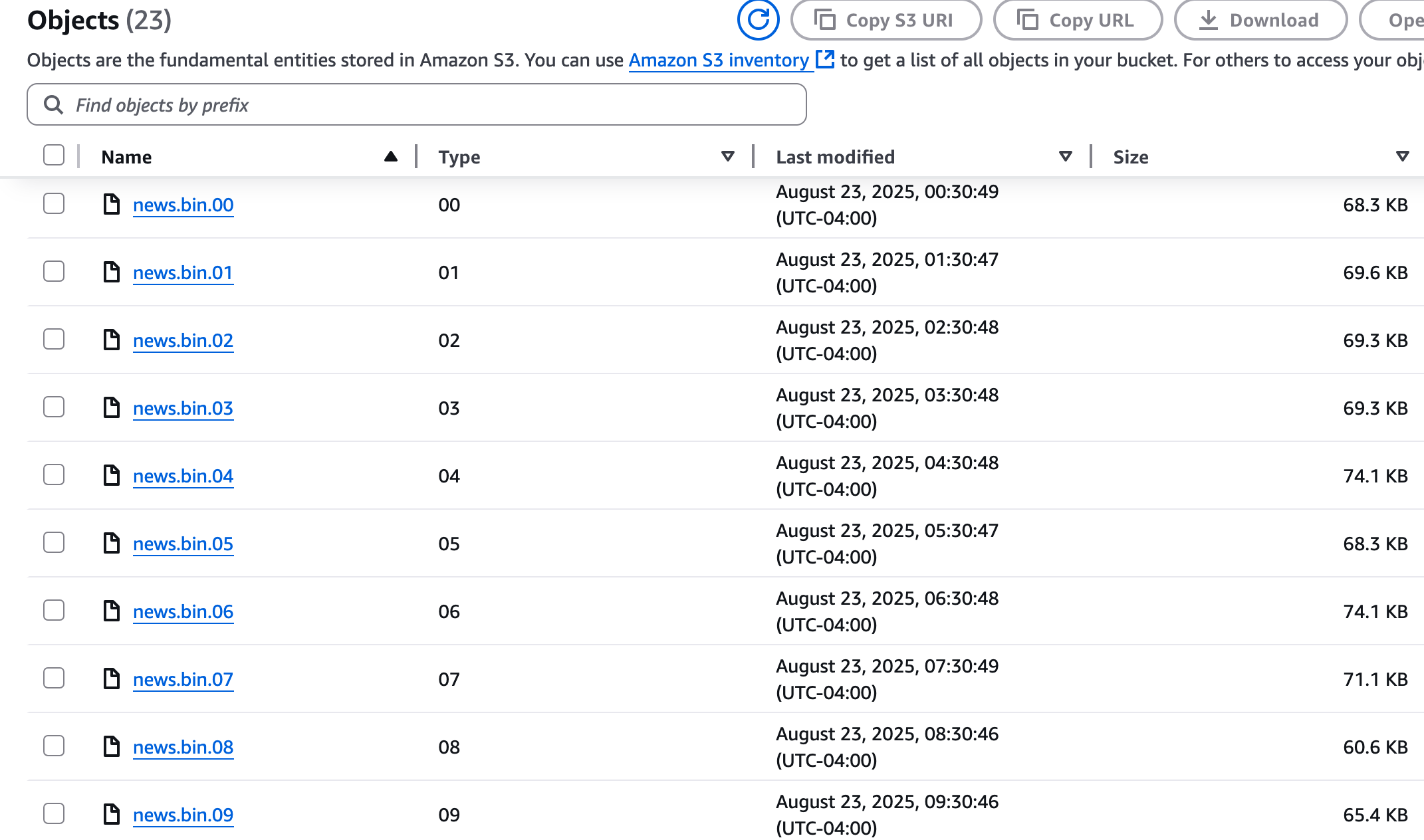
After going through the WiiLink install process, if we fire up mitmproxy and take a look at what the Wii is doing now, we’ll see that it’s actually requesting files from a different domain: “news.wiilink.ca”. But this time, it manages to fetch news.bin.00 and keeps requesting files all the way up to news.bin.23.
The News Channel just successfully fetched 24 hours worth of news from this server.
Great! Somehow, the WiiLink folks got this all to work. And, best of all, they’ve opened-sourced their work (GitHub). The plan is looking really feasible at this point!
At a high-level, there are two steps to tackle, then:
We have to make the News Channel fetch files from a server we control
We need to actually generate binary files with the content we want
Step 1: Patching the News Channel to redirect to our domain
If we follow along with WiiLink’s installation guide, the critical step seems to be installing a patched version of the News Channel. Looking at their GitHub org, we find a WiiLink24-Patcher project. Searching for the “News Channel” in the source code, we find this line in patch.cs which references a VCDIFF encoded News_1.delta patch.
Side note - it’s only while writing this blog post that I realized I had been looking at the “wrong” repo; WiiLink’s guide now recommends using the Python-based WiiLink-Patcher-GUI instead of the CLI patcher.
After downloading the .delta file locally, we can use the xdelta CLI to print out some information on what the patch is supposed to do:
Okay, so we’re looking for a 0000000b.app file and want to save the patched binary as news.dol. Based on the WiiLink install instructions, we know we should be dealing with a WAD file, so let’s keep digging to see if we can find out where 0000000b.app might be hiding.
Learn more about the WAD file format on wiibrew.org.
From the repo’s README.md, we know the patcher uses libWiiSharp for it’s WAD file management during the file patching processing (source). But at this point, I’d rather avoid using C# if I can. And besides, I know for a fact we’ll want to use Go in order to more easily leverage existing tooling from the WiiLink team.
Thankfully, there’s a really handy Go library called wadlib that comes to the rescue here. We’ll be using it for all our WAD management needs.
So, where is 0000000b.app? Looking at LibWiiSharp’s WAD.cs file, we can spot how it unpacks .app files from a WAD file. Namely, it defaults to using the numeric “Content ID” inside each “Content” metadata and then converts it to an 8-digit hexadecimal string (source).
You can read more about Title metadata (“TMD”) and Content metadata (“CMD”) on wiibrew.org
Armed with this knowledge, we can use wadlib to create a quick file extraction script and see if we can find our 0000000b.app. It can go something like this:
// ignore error handling for brevitywad,_:=wadlib.LoadWADFromFile("news.wad")titleMetadata:=wad.TMDcontentMetadata:=titleMetadata.ContentsoutputDir:="extracted_wad/"os.MkdirAll(outputDir,0755)fori:=0;i<len(wad.Data);i++{data,_:=wad.GetContent(i)contentID:=contentMetadata[i].ID// "%08x" means 0-padded 8 digit hexfilename:=filepath.Join(outputDir,fmt.Sprintf("%08x.app",contentID))_=os.WriteFile(filename,data,0644)log.Printf("Extracted: %08x.app (size: %d bytes)",contentID,len(data))}
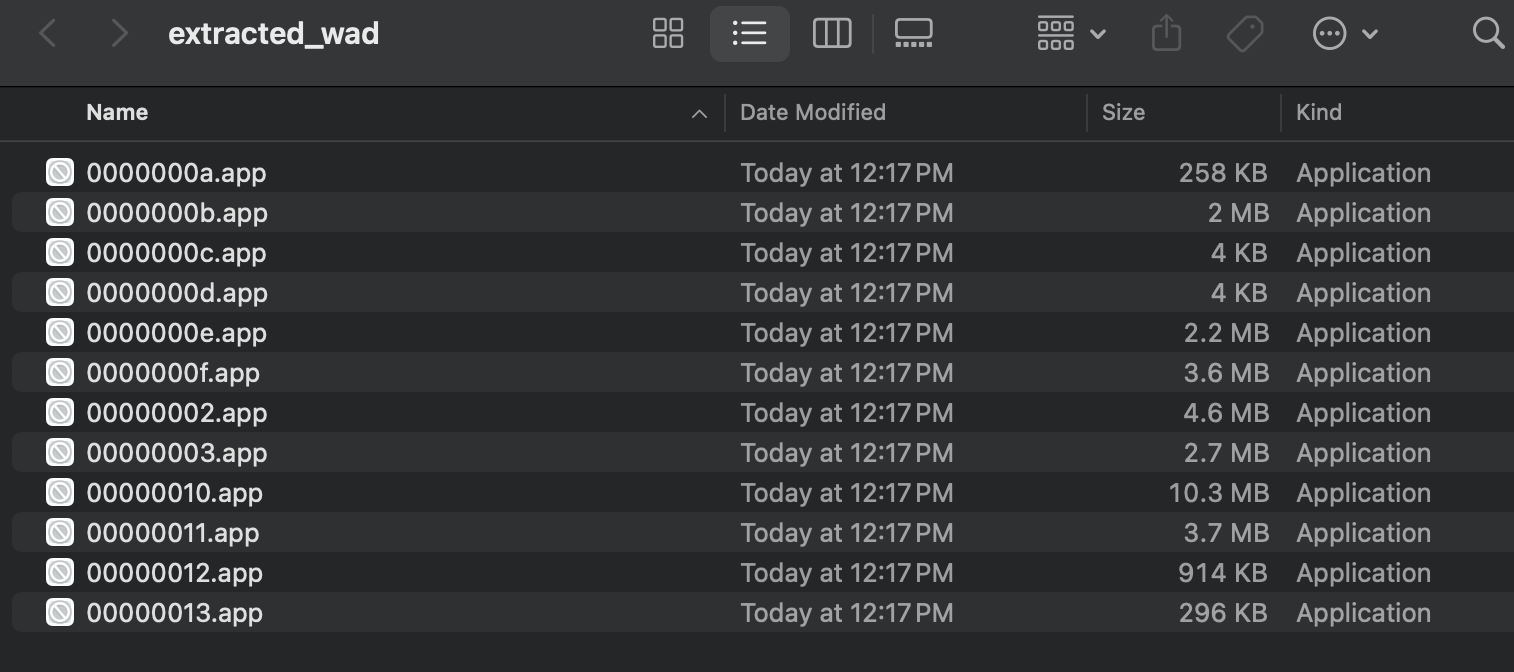
When news.wad is the official (v7) News Channel WAD file, this script successfully extracts 12 .app files.
There’s definitely a 0000000b.app there, but could it be the file we’re looking for?
What we really need to do at this point is go ahead and apply the News_1.delta patch to this 0000000b.app file manually. That way, we can compare the before/after binaries and see what changed. We can use xdelta again to actually apply the patch. Running xdelta3 --help says:
And that… seemed to work? We have a news.dol file, as expected. Now what?
Investigating binary file changes
We could do a binary diff of these files and start going through each change, but we already know at least one thing that should have changed based on our previous mitmproxy experiments: instead of performing requests to “news.wapp.wii.com”, the patched WAD should instead use “news.wiilink.ca”.
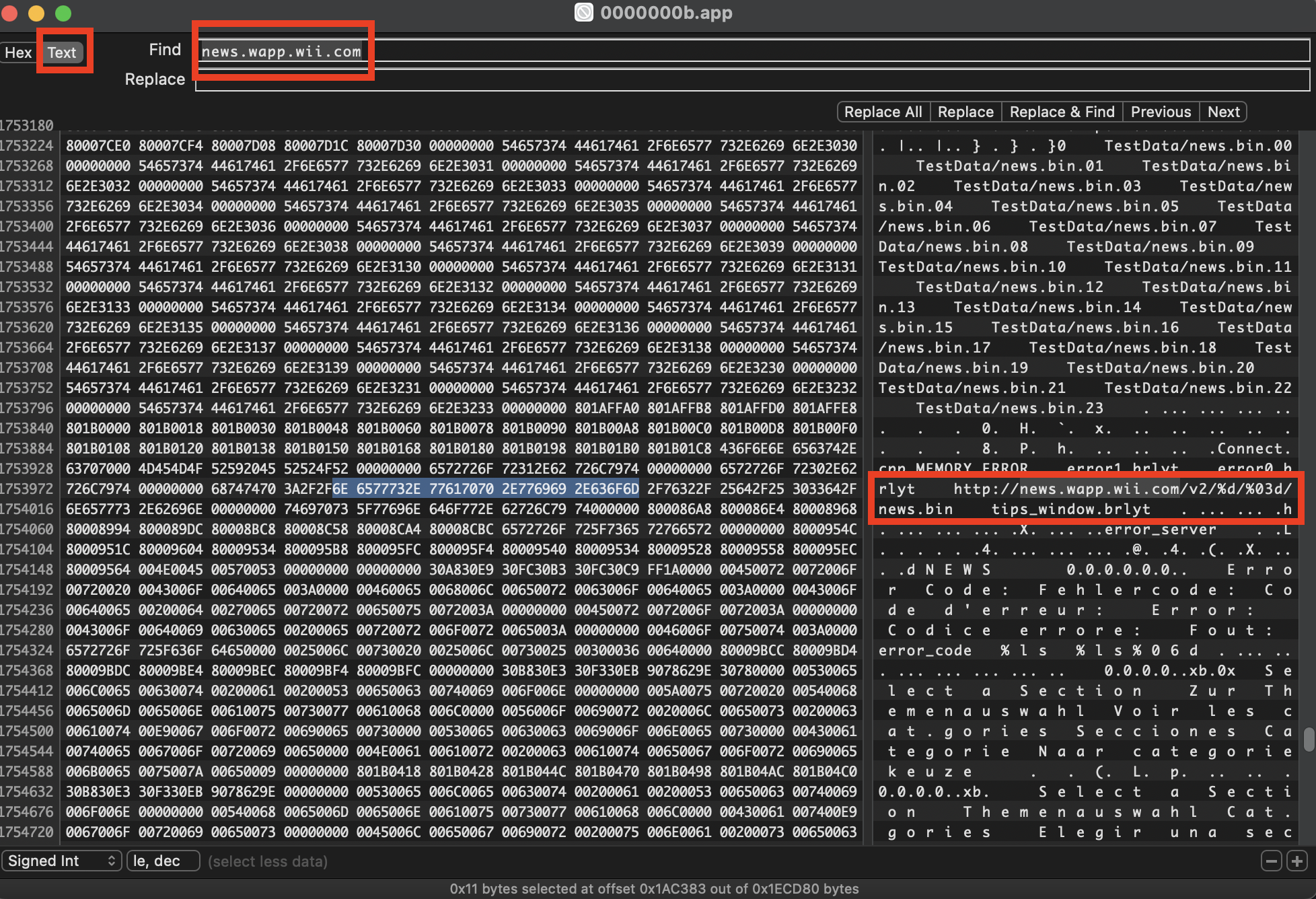
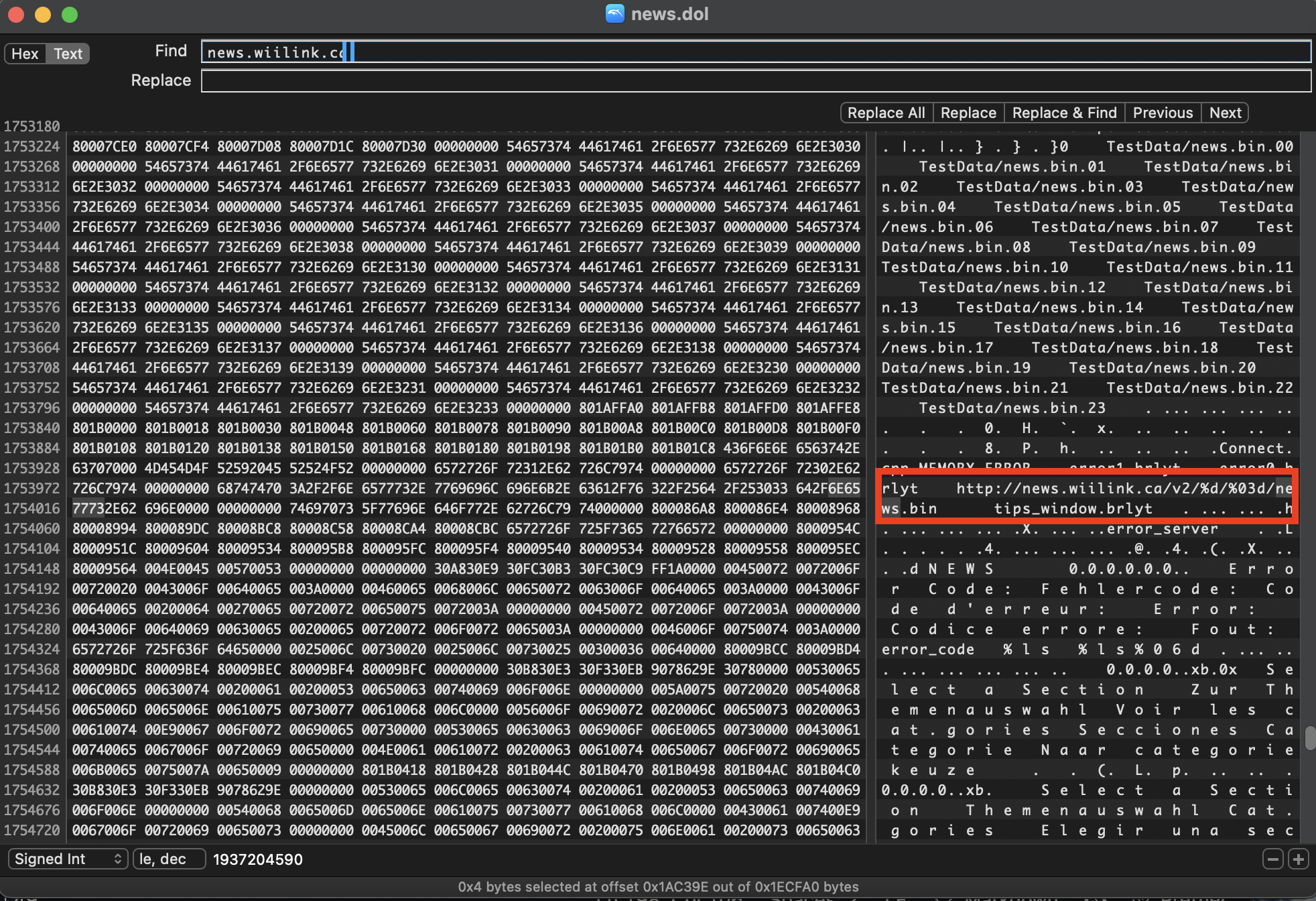
Using a tool like Hex Fiend (which also has binary diffing capabilities in case we need them), we can try searching for text inside the binary. If we try searching for “news.wapp.wii.com” on the original 0000000b.app file, we can actually find a match!
Sure enough, if we inspect the patched news.dol file we will find no mention of the original URL. Instead, the “http://news.wiilink.ca” domain is visible at the same location (offset 0x1AC37C).
Note that the URL contains only two printf-style format strings (%d and %03d); the News Channel itself must be appending the hourly suffix (like .00) when fetching data.
If we’re lucky, simply overwriting the binary file’s original URL with our own custom URL might do the trick. It’s worth a try!
In order to validate this hypothesis, I wrote a small Go utility for performing the necessary text replacement. Here’s an excerpt of the important bits:
// ignoring error handling for brevityconstOriginalURL="http://news.wapp.wii.com/v2/%d/%03d/news.bin"constNewURL="http://wii.rauln.com/news/%d/%03d/news.bin"wad,_:=wadlib.LoadWADFromFile(wadPath)// Get decrypted content at index 1 (record with ID "0000000b")content,_:=wad.GetContent(1)// byte slice of 44 bytesoriginalContent:=[]byte(OriginalURL)// 43 bytes in our URL's casenewContent:=[]byte(NewURL)// Pad the new URL to match original length (44 bytes)paddedURL:=make([]byte,len(originalContent))copy(paddedURL,newContent)// Find the offset (index) of the URL to patch inside the byte sliceoffset:=bytes.Index(content,originalContent)// Patch the URLcopy(content[offset:offset+len(originalContent)],paddedURL)_=wad.UpdateContent(1,content)// Save the updated WAD file_=os.WriteFile(outputPath,wadBytes,0644)
go build
wiinewspr-patcher news.wad patched_news.wad
It should perform the URL rewriting in memory and provide us with a valid WAD file (patched_news.wad) we can then go ahead and install on Wii hardware.
Finally, we can go back to running mitmproxy and opening the newly patched News Channel. Once the channel shows the “Downloading…” splash screen, we’ll spot requests going out to our expected domain.
It works! Now all we need is to… actually generate valid news files for the News Channel to work.
I mentioned previously that I knew using Go would come in handy later, and it’s specifically because the WiiLink team has a project called NewsChannel written in Go which contains the source code for generating the binary news files they serve from “news.wiilink.ca”.
I’m not going to go over all the implementation details here. I just want to highlight some of the main file creation steps in case you’d like to read more:
obtain articles and metadata from configured sources (like NHK, source)
process all data in a specific order into a bytes buffer (source)
compress the data using LZ10, sign it with RSA, then write to disk (source)
the file name is written using a specific string interpolation (source, this is how I first found out about the language/country codes used in the News Channel data URL!)
Fun fact: LZ10 is apparently a Nintendo-specific variant of the LZ77 compression algorithm, used in some form or another on Game Boy Advance, Nintendo DS and Wii systems. wii-tools/lzx has the Go source for the LZ10 compression used here.
In any case, for our purposes, it’s doing more than we need in terms of source handling: it can generate news binaries from a variety of sources and supports different languages and regions.
For this project, I am making the following assumptions and tradeoffs:
I will be using “English” as the language and “US” as the country code for the source URL path since my Wii console is configured as such. There is no separate Puerto Rico country code option, which is curious considering that there is a separate option for the US Virgin Islands.
I am not interested in supporting any other news sources from around the world, so the “Globe” feature for the News Channel will not be useful.
I’m hardcoding the latitude and longitude of Puerto Rico’s capital into the binary file to avoid having to process or guess location data from each article entry.
Modifying WiiLink’s generator to support Puerto Rican news
I went ahead and forked the NewsChannel repo into WiiNewsPR, added flag support to control article caching and binary output paths (you’ll see why this was necessary soon), removed all the existing sources and added a new one: El Nuevo Día (“ENDI”).
I picked ENDI only because it’s the only local newspaper website I could find which still supports RSS. Unfortunately, the feeds only contain a snippet of the actual article. On the bright side, most articles do contain images and we can use separate feeds to help categorize articles in the News Channel (source).
By the way, I experimented with GoOse for (spanish language) article extraction on other news websites and the results were… unsatisfying, to say the least.
Final setup requirements for proper News Channel support
Two quick things we’ll need in order to get this all to work:
We need to sign each binary news file with a custom RSA key for the Wii to process the file (source). We can use openssl for this (note the -traditional option):
openssl genrsa -traditional -out Private.pem 2048
We need a (really) low quality logo for our source. ImageMagick easily solves for this:
Then, we can use Go embeds to include the logo in the Go binary (source).
Finally, we can build the Go binary and run it in order to generate a news binary in ./v2/1/049:
go build
./WiiNewsPR
This successfully generates a news.bin.NN file.
Now we just need 24 of these, since the News Channel will actually fail to load if not provided with all 24 files. We could run this script every hour for the next 24 hours… or, we could take the shortcut of copying the current hour’s file into all other hourly values.
Regardless, it’s about time to test out all this effort. With 24 files uploaded to our storage provider (AWS S3), and the patched News Channel configured to fetch these from our custom domain, we can start up the channel and observe the fruits of our labor.
After the (slow!) requests finish one by one, seeing the articles pop up was immensely satisfying. Being able to tinker with and learn more about these nostalgic consoles so many years later is a real joy for me.
Bonus step: Automating hourly news updates with AWS Lambda
Copying files into the S3 storage bucket is all well and good, but it would be great to have a continuously-updating, hands-off solution that generates the news binaries for us. A simple (and basically free) way to solve for this would be to bundle up the WiiNewsPR Go executable into an AWS Lambda function and have that run hourly via EventBride, and then uploading the generated news binaries over to our storage bucket.
Here is where the extra flags for WiiNewsPR come in: we need to be able to control file creation because /tmp is a Lambda’s only writeable file system.
See full Lambda handler source on GitHub: handler.go
We can then leverage the Serverless framework for a quick infra-as-code setup. Here is a snippet of the configuration:
service:wiinewspr-generatorprovider:name:aws# ...environment:# ...TZ:America/Puerto_Rico# we need Lambda to generate files postfixed with the correct "currentHour"# ...events:- schedule:rate:cron(30 * * * ? *)# run every hour:30name:wiinewspr-every-30pasthourdescription:Generate Wii News PR binary file every hour at 30 minutes pastpackage:patterns:- bootstrap# compiled Lambda handler- WiiNewsPR# compiled binary news generator- ../Private.pem# we need to include the Private.pem file for file signing
See full serverless configuration on GitHub: serverless.yml
Some things to call out here:
We want to make sure to run the Lambda in Puerto Rico’s timezone so that time.Now() returns the expected hourly integer.
We want to give the Lambda a higher than expected memorySize so that its CPU scales accordingly; it turns out that lz10 compression is a big bottleneck on the smallest supported Lambda CPU and can easily time out at 30 seconds.
If we leave this setup running for 24 hours, our storage bucket will get populated with 24 files and continuously be updated with the latest news!
Now I can get up in the morning, grab a coffee, and browse the local news on my Nintendo Wii like it’s 2007.
Today, I switched the static file generator for this website from Pelican over to Hugo. The process was smooth, only requiring minimal changes to source files (mainly front-matter syntax). I modified the hugo-lanyon theme only a little bit to get it looking how I wanted.
An archived snapshot of the old Pelican source files is here. Before Pelican, I used Jekyll, which is archived here.
I’ve been reading up on JavaScript these past few months. I feel like there used to be a stigma against the language during my time at university, and maybe there still is. I dug up and read a book I once bought called JavaScript: The Good Parts by Douglas Crockford. It’s outdated now, but I used to joke that if “The Good Parts” could be described in 172 pages… Well, suffice it to say, I was not very encouraged.
Well, I’ve come around. Modern JavaScript is fun to write and, being a web-first language, it entices you to think about problems in a different way from other languages I’ve tried. After going through some basic language training, it’s time to see how to set up a simple web server, JavaScript style.
A selection of flavors to choose from
Once you start researching your options, you may feel the onset of analysis paralysis. There are a lot of different packages and projects to choose from. I thought it would be fun to write a simple echo server using a few of them, as an excuse to go through their tutorial and docs.
Setup
Simple as pie. For sending requests, I like to use HTTPie. We’ll use it to easily send some query parameters through localhost on port 3000. I should mention that I am running NodeJS v11.7.0 and HTTPie v1.0.2.
consthttp=require("http");consturl=require("url");constPORT=3000;constserver=http.createServer((req,res)=>{res.writeHead(200,{"content-type":"application/json"});constquery=url.parse(req.url,(parseQueryString=true)).query;res.end(JSON.stringify(query));});server.listen(PORT,err=>{if(err)throwerr;console.log(`Now listening at port ${PORT}...`);});
Testing it out with http :3000 user==1, we get the following response:
HTTP/1.1 200 OK
Connection: keep-alive
Content-Type: application/json
Date: Sat, 26 Jan 2019 22:49:34 GMT
Transfer-Encoding: chunked
{"user": "1"}
A nifty, if plain, echo server. We should expect the response from all the servers in this blog post to have the content-type header set to “application/json” and the status set at 200, so I will omit the rest of their responses.
Even though the code is quite simple, we still had to work for that echo response. Other packages highlighted in this post will automatically parse the query string from the URL, but we didn’t have that luxury here. The response also had to be manually JSON-stringified. Diving a bit deeper (down the prototype chain), we find that our server, from http.createServer(), is an EventEmitter. It’s been instructed to listen for request events at port 3000. The req and res streams (notice there are two…) represent the client side request and the server side response, respectively. Moving on to the rest of the server-side flavors…
2) NodeJS Core: The Sequel
But before that, did you know there is a core NodeJS module called http2? Actually, back it up, did you know there is a version 2 of HTTP?! In any case, this module is a stable part of NodeJS now, so I believe it should get it’s own spot.
consthttp2=require("http2");constserver=http2.createServer();consturl=require("url");constPORT=3000;server.on("error",err=>console.error(err));server.on("stream",(stream,headers)=>{constresponse=url.parse(headers[":path"],true).query;stream.respond({":status":200,"content-type":"application/json"});stream.end(JSON.stringify(response));});server.listen(PORT);console.log(`HTTP2 Server now listening at port ${PORT}...`);
We’re in it now. Instead of two separate streams, the server now responds to the stream event and provides a duplex stream. We obtain the query parameters via the headers object, and parse it similarly to how it was done using the original http example.
By the way, the above code won’t work on browsers… While HTTP/2 does not enforce encryption, modern browsers seem to have conspired to enforce it. There exists an http2.createSecureServer which can work with browsers. But without setting up a secure server, how will we (taste) test this flavor? Even HTTPie has trouble with it! I tried the experimental HTTP/2 plugin, but could not get it to work.
Let’s roll up our sleeves and write a basic HTTP/2 client in Node to get this example to work.
It works! This flavor we really had to work for, but it was worth it in the end.
(P.S. If you noticed the colon to the left of "path" and "status" in the code and don’t know what they are, may I introduce you to: pseudo headers)
3) Express
Here we have the Express framework, probably the most popular of the NodeJS backend libraries.
constexpress=require("express");constapp=express();constPORT=3000;app.get("/",(req,res)=>{res.json(req.query);});app.listen(PORT,()=>{console.log(`Express listening on port ${PORT}...`)});
That app object has access to a lot more than what is seen here, including a powerful method chaining concept called middleware.
4) Hapi.js
I had never heard about Hapi before researching this topic. Here’s how it looks.
Probably the least popular of the frameworks in this list. It strives to be a strict implementation of the REST architectural style.
constrestify=require("restify");constPORT=3000;constserver=restify.createServer();server.use(restify.plugins.queryParser());server.get("/",(req,res,next)=>{res.json(req.query);});server.listen(PORT,()=>{console.log(`Restify listening at port ${PORT}`);});
constkoa=require("koa");constapp=newkoa();constPORT=3000;app.callback(console.log(`Koa listening on port ${PORT}...`));app.use(asyncctx=>{ctx.set({"content-type":"application/json",status:200});ctx.body=ctx.request.query;});app.listen(PORT);
From the little time I’ve spent with all these frameworks, I think I like the look of Koa the most. This was just a very quick look at making a barebones server in all these different packages. Each one has their own ecosystem and quirks, pros and cons. I recommend going through their documentation to see what they can really offer.
Next up, a selection of flavors from the server side of Python frameworks.
In the web development space, tools and best-practices change quite frequently. At one point in the not-so-distant past, a LAMP stack was the go-to approach for launching a web application. These days, PHP is the #8 most popular programming language (according to a company with the name “The Importance Of Being Earnest”), while Python and JavaScript rank above it.
One of the reason for this change has to do with the growing trend towards microservice architectures. Together with the need for rapid prototyping and the onset of agile development methodologies, Python and other languages have swept in and stolen the LAMP stack’s lunch.
So what is the new stack? A complex question with opinionated answers… Here is a recent community discussion on Hacker News: Go-to web stack today?
But wow, there are so many things to learn and keep up to date with nowadays! To help alleviate this, I’d like to work on a side-project using full-stack technologies. In particular, I want to use the following tools to build a fullstack app:
Django (backend)
Ember (frontend)
Docker (development/deployment)
Postgres (database)
… plus many more! (think git, pipenv, serverless, test-driven development… Maybe type-hints, GraphQL and data visualization too?)
The idea: A web app for keeping track of your video game backlog
No shame: the project is most definitely a copy of The Backloggery, a great site that I use often. However, as far as I know, The Backloggery is built in PHP, probably on a LAMP stack or similar. So I thought I would take a crack at building a small subset of the Backloggery features, on a more modern stack.
I like this idea because it comes with a well-defined problem set. I can already envision the database schema and how to build the backend. But as I mentioned, this project is going to involve the entire stack. That means I gotta learn some frontend JavaScript. In this series of blog posts, I document my experience.
I should say, the reason I picked Ember and not (the elephant in the room) React is that in my day job, we work with Ember and so this is a skill I would like to improve! Besides, we all know Postgres is the real elephant here, right? Let’s move on.
The app: vg-stack
I had to name my repo something!
In all honestly, I like the name because it hints at the purpose of the project (practicing the web stack) while at the same conjuring a mental image of a bunch of video games stacked on top of each other.
Setting up
For this first part, I’m going to build a backend skeleton using Django and the awesome Django REST framework package. As already mentioned, our database will be the ever-popular PostgreSQL and we are aiming for best practices in all parts of the stack. That includes deployment/development tools and environments! That said, I’m going to assume knowledge of the tools used and explain only the highlights.
Project Structure
In fact, I’m going to skip most of the project setup entirely and just go with a pre-built template! I like William Vincent’s drfx, so let’s go ahead and clone that:
The template provided comes with a lot of best practices built in. We can build on top of it and get going quickly!
Dependencies
We’re going to install the following extra packages for now:
python-dotenv to comply with mandate III of The Twelve-Factor App, psycopg2-binary to use PostgreSQL as our database, black to format our code and factory_boy to improve our tests maintenance.
$ pipenv install python-dotenv psycopg2-binary
$ pipenv install --pre --dev black factory_boy
We install black and factory_boy as development dependencies and tell Pipenv to allow the pre-release black package through!
Django Settings
Let’s get started setting up our project.
First, create a .env file for use with python-dotenv.
The database env variables can stay as they are, since those settings happily coincide with the default database, user and password in the Postgres Docker Image!
Now, replace “drfx” with “vgstack” everywhere it appears in the project, such as in values for ROOT_URLCONF, WSGI_APPLICATION and even the main “drfx” directory!
We also modify our settings file in order to use python-dotenv. In the end, it should look like this:
# vgstack/vgstack/settings.pyfrompathlibimportPathimportosfromdotenvimportload_dotenvBASE_DIR=Path(__file__).resolve().parent.parentdotenv_path=BASE_DIR/'.env'load_dotenv(dotenv_path=dotenv_path)# SECURITY WARNING: don't run with debug turned on in production!DEBUG=os.getenv("DEBUG")# SECURITY WARNING: keep the secret key used in production secret!SECRET_KEY=os.getenv("SECRET_KEY")# Allow communicaiton from our Docker container if DEBUG=TrueALLOWED_HOSTS=["0.0.0.0"]ifDEBUGelse[]# ...ROOT_URLCONF="vgstack.urls"# ...WSGI_APPLICATION="vgstack.wsgi.application"# DatabaseDATABASES={"default":{"ENGINE":"django.db.backends.postgresql","NAME":os.getenv("DATABASE_NAME"),"USER":os.getenv("DATABASE_USER"),"PASSWORD":os.getenv("DATABASE_PASSWORD"),"HOST":os.getenv("DATABASE_HOST"),"PORT":os.getenv("DATABASE_PORT"),"CONN_MAX_AGE":7200,}}# ...
Notice I replaced the os.path call for the new kid on the block: Pathlib. I’m trying to make that a habit!
Docker
Let’s build a simple Python Dockerfile!
# vgstack/Dockerfile# pull the Python official base image, slimmed downFROMpython:3.7-slim# set environment variblesENV PYTHONDONTWRITEBYTECODE 1ENV PYTHONUNBUFFERED 1# set work directoryWORKDIR/usr/src/app# install dependencies with PipenvRUN pip install --upgrade pip && pip install pipenvCOPY ./Pipfile /usr/src/app/PipfileRUN pipenv install --system --skip-lock# copy project over to imageCOPY . /usr/src/app/# specify our entrypointENTRYPOINT["./docker-entrypoint.sh"]
And a nice docker-compose file to help us run the project and related services.
We can see that we are persisting the Postgres database via Docker volumes. Also, we are taking advantage of the env_file command to load in our previously created file. Finally, we call the entrypoint command to run a shell script instead of running an in-line command.
The following entrypoint script is a modified version of the one found in José Padilla’s notaso project. It attempts to use a PostgreSQL cursor every second, and keeps trying until a connection succeeds. Then, it proceeds to migrate the Django models and runs the development server.
We can now use docker-compose to build our images and start our development server!
$ docker-compose up --build
Visiting http://0.0.0.0:8000 on your browser should show… a 404 page. That’s by design! There’s no home page yet. Pointing the browser over to http://0.0.0.0:8000/admin/ should show a log in screen, which means all is well! You can create a user by opening a new terminal window and using Python inside the running Docker container.
$ docker-compose exec web python manage.py createsuperuser
You may want to start the containers in detached mode so you don’t have to keep opening terminal windows.
$ docker-compose up -d
Applying a black coat of paint
After all that, it’s nice to make sure our code looks nice and consistent. For that, we can use the opinionated Python code formatter, black.
First, create a pyproject.toml file in the root of the project, in order to customize black’s settings if we so choose.
Now that the project is set up with best practices thanks to drfx and we have a nice development workflow using Docker, we can get to work writing the actual bulk of the backend. In the next part, we will write the models, serializers, views and (last but not least) the tests that make up our backend code.
A previous version of this post mentioned using Angular for the frontend, as this was what my team was using at the time. I’ve since switched jobs, and I want to focus on using my current team’s frontend tech!
I would consider Python to be the programming language I’m most comfortable writing code in. There’s plenty to love, and one of its more recognizable features is its simple to read syntax. I’ve heard the phrase “executable pseudocode” thrown around before, and its easy to see where the comparisons come from.
A great side effect of sporting such a relatively simple to understand syntax is its mass appeal, with people jumping in with little programming knowledge and using Python to jump start their new coding adventures.
Its not hard to get carried away and forget that, despite the focus on readability, code is not the same as prose. Its always worthwhile to keep the subtleties of a particular language in mind. That being said, this post is about the bug I created when I forgot about the (perhaps not so subtle) distinction between identity and equality in Python, and what I learned from that mistake.
Let’s review the fundamentals before diving into the particulars.
Object Equality
Object equality refers to the intuitive notion of equality from mathematics. Sounds simple enough.
From the docs, we see that “objects of different types, except different numeric types, never compare equal.” We can test this out as follows:
# Comparison between objects of different types, one non-numericx=1y='1'x==y# False, x and y are different objects# Comparison between different numeric typesy=1.0type(x)# <class 'int'>type(y)# <class 'float'>x==y# True
We can also define equality on our own objects by writing an __eq__() dunder method:
classGoomba:def__init__(self,value):self.value=valuedef__eq__(self,other):"""
Goomba is equal to other if the sum of their values is even
"""if(self.value+other.value)%2==0:returnTruereturnFalseclassKoopa:def__init__(self,value):self.value=valuedef__eq__(self,other):"""
Koopa is equal to other if the sum of their values is odd
"""if(self.value+other.value)%2==0:returnFalsereturnTruegoombario=Goomba(1)goombella=Goomba(2)kooper=Koopa(1)koops=Koopa(2)goombella==goombario# False, 1 + 2 = 3, 3 % 2 = 1goombario==goombario# True, 1 + 1 = 2, 2 % 2 = 0goombario==kooper# True, 1 + 1 = 2, 2 % 2 = 0goombella==kooper# False, 2 + 1 = 3, 3 % 2 = 1goombella==koops# True, 2 + 2 = 4, 4 % 2 = 0
You may have noticed something peculiar from the example: due to the way equality was defined in the above classes, the order of the operands matters (the operation is not symmetric in this case).
Digging a bit further, we can see from the value comparisons for expressions docs page that it is intended for the == operator to be a test for an equivalence relation. So the above example, where symmetry is not observed, would not be consistent with the way Python defines equality. In any case, object equality is pretty straightforward from a practical point of view.
Object Identity
For me, the notion of “identity” is a bit more vague than “equality”. What does it mean for two objects to share an identity? While perhaps not as intuitive as object equality, object identity is not much more complicated. In Python, the identity operator is appropriately known as the isoperator.
Basically, a is b if and only if id(a) == id(b), where a and b are objects and id(x) is the memory address of x. So, for two objects to be “identical”, it must be the case that they are the same exact object! In other words, if two variables share the same object address, there are in fact not two objects but rather two references to the same object.
1is1# Truex=[1,2,3]y=[1,2,3]x==y# Truexisy# False
There are some subtleties to this that may not be immediately apparent. For example, [1, 2, 3] is [1, 2, 3] = False. Meanwhile, (1, 2, 3) is (1, 2, 3) = True. The reason is, as you may suspect, that lists are mutable while tuples are not.
Equality vs Identity in Python Strings
Well, what about strings? We know that strings in Python are immutable objects. And as we might expect, 'hello, world' is 'hello, world' = True! But here’s where things start to get interesting…
# Example 1'hello, world'is'hello, world'# True# Example 2str_1='hello, world'str_2='hello, world'str_1isstr_2# False (!)# Example 3str_1='helloworld'str_2='helloworld'str_1isstr_2# True (?!)# Example 4str_1='hello, world'str_2='hello, world'str_1.replace(', ','')isstr_2.replace(', ','')# False(!?!)
What gives? And to make things more interesting, the above code was executed line-by-line on the interactive shell. If you copy the above code into a source file and run the entire file (while printing the results), you will find that the first three conditions are True (the last one remains False). Which means that the second identity operation just changed truth values! And how come removing the comma and whitespace from both strings at the end there didn’t make the identity check True again? The key to answering all these questions is: string interning! Let’s talk about it.
String Interning, or “Compare strings in O(1) instead of O(n)!”
This concept was completely unknown to me until very recently. String interning is the process by which a particular string object can be stored in an internal dictionary for faster lookups. Further assignments of the same string contents will yield a reference to this stored object instead of creating a new object.
In practical terms, interning a string allows for lower memory usage as well as a performance boost in matching via string equality. That is, instead of relying on standard string matching algorithms to determine whether or not two strings are the same (i.e., contain the same characters in the same order), you can simply check whether or not they are references to the same object. This allows an equality check to be optimized as an identity check, which typically means that an O(n) character-by-character operation has been optimized all the way down to an O(1) numerical address comparison. This is quite the optimization, which is why Python natively interns strings based on a set of internal rules. And if we examine some of these rules, we’ll find answers to the questions left unsolved in the previous section.
For example, it turns out that Python natively interns all strings which contain only ASCII letters, digits and the underscore character. This explains what happened in Example 3. Both strings are pure ASCII and therefore got interned by Python (conversely, their comma-and-whitespace-containing hello, world counterparts from Example 2 were not interned by this rule). Also, it’s important to note that native interning occurs at compilation time. This fact explains why False was the result in Example 4. It would seem that the replace method turned our comma-and-whitespace-containing strings into intern-me-ASCII strings, but in fact the string replacement occurred at runtime, and thus never got the chance to be interned natively.
But how does this explain Example 1? Well, Python was smart enough to realize that 'hello, world' is 'hello, world' is an attempt to compare the reference of two immutable objects which happen to be the same and it optimized accordingly. Now, how come the code exhibits completely different behavior when running in the shell versus in a source file for Example 2? Notice that this same scenario plays out a little differently depending on the execution environment. This is because, in the shell, the code is fed to the Python interpreter line-by-line, as opposed to file execution, where the Python has access to all the code in the file at once. Again, Python was smart enough to optimize the strings when it had forward-lookup capabilities available, but not so when it did not “know” what the next line would be (which was the case for Example 1, where it did optimize).
Phew! Now, let’s look at how we use manual string interning and get the is operator to work as we expected it to originally:
There it is! Two different references to the same object. We saved memory by not creating two different objects for the same string, we achieved a performance boost by comparing references instead of the contents of the strings, and we learned a lot about Python strings and objects along the way.
From a bug, knowledge
I mentioned at the top that I became interested in this whole string identity vs equality thing because of a bug I found (a.k.a created) at work. Here it is, in all its glory:
ifdatabaseisnot'some_database_alias':# ...
At first glance, there may not seem to be much of a problem here. However, if the code that is expected to run after the conditional expression is of critical importance, then it pays to make sure that the conditions under which the expression evaluates to true are well understood.
Then came the time for that line of code to do its one job…
It didn’t work. I wrote an identity comparison where I should have written an equality comparison instead. The moral of the story here: is is not ==.
Conclusion
What started out as a casual review of Python syntax caused by a simple enough bug turned into a curiosity-driven deep dive into Python string internals and comparison operators. All in good fun. The following article by Adrien Guillo was very helpful and goes into the lower-level goings on of CPython’s string interning mechanisms: The internals of Python string interning. Satwik Kansal wrote another, higher-level introduction to the topic: Do you really think you know strings in Python?
I don’t know what inspired it, but recently I got the idea that programming for an old game console would make for a fun project. Apart from giving me an excuse to write code in a language other than Python, it’s something I’ve wanted to do ever since I learned that programming was at the heart of all the great games I’ve played throughout the years. So, I decided to find out how feasible it would be to program for one of these old school gaming systems.
The Game Boy Advance was my first research subject. While reading up on the GBA, I learned that the original Game Boy (model “DMG-01”) had a more well-established homebrew community, compared to the Game Boy Advance. There is a lot of great documentation out there on developing for the Game Boy! Just visiting the awesome-gbdev repo convinced me to choose the original Game Boy as my retro coding platform.
I’d like to blog about my experience as a form of self-motivation. I’ll write about the process from the start and then be able to look back and see how I’ve progressed along the way! And if someone happens upon these posts, I hope they find them useful.
NOTE: I’ll be using the following Japanese-language blog post as a template for this one: 開発環境の導入.
Development Environment on MacOS
As the title says, I am working towards a functional GB dev environment on MacOS (specifically High Sierra, version 10.13.4). Sadly, most of the good tools for Game Boy development are Windows-only. But that’s okay! We can get away with using Wine to run the best of them.
An introduction to the tools
The development scene for the Game Boy is centered around two programming languages: C and assembly. My personal preference was to start developing in C. I’m using Harry Mulder’s Tile Designer as well as his Map Builder to manage the graphical aspects of developing for a video game console. Finally, the bgb emulator is the standard for testing and debugging Game Boy games.
Getting a C compiler up and running:
The tool of choice here is the Game Boy Developers Kit (GBDK). The installation may be tricky on MacOS. There are a couple of alternative installation methods around, but I went for the following:
$ git clone https://github.com/x43x61x69/gbdk-osx
$ cd gbdk-osx
$ mkdir -p sdcc/bin
$ sed -i '' -e '1005d' sdcc/src/SDCC.y
$ make
$ sudo mkdir /opt && sudo cp -r build/ppc-unknown-linux2.2/gbdk /opt
make will proceed to build GBDK. Note that the above commands do some extra stuff besides building the compiler libraries. Click on them below to learn more about why they are required if we want the build to succeed.
Make sure to add the path to the new binaries to your PATH:
$ exportPATH="/opt/gbdk/bin:$PATH"
Ideally, you would include that line in your .bash_profile or similar. The compiler’s front-end (called lcc) would then be easily accessible.
You could also choose to leave the binaries in-place and make a symbolic link, like so:
$ sudo ln -s build/ppc-unknown-linux2.2/gbdk /opt
In that case, you would have to adjust your PATH accordingly.
Building a minimal Game Boy game: a sanity check
Having come this far, let’s make something a bit more involved than a printf("Hello, world!"); for the Game Boy, shall we?
Create a file and then copy-paste (or type by hand!) the following code:
#include<stdio.h> // printf(), delay()#include<gb/gb.h> // joypad(), J_UP, J_DOWN, ...voidmain(){// Loop forever
while(1){// Check the status of the Game Boy Joy Pad
switch(joypad()){// If the UP button is pressed...
caseJ_UP:// Display "Up!" on the screen
printf("Up!\n");// Then wait for half a second...
delay(500);// Go back to checking the status of the Joy Pad
break;// And so on
caseJ_DOWN:printf("Down!\n");delay(500);break;caseJ_LEFT:printf("Left!\n");delay(500);break;caseJ_RIGHT:printf("Right!\n");delay(500);break;default:break;}}}
Save the file as first.c and proceed to build the code:
$ lcc first.c -o first.gb
Hopefully everything compiled correctly! You’ll know it worked if lcc stays quiet after compiling, thus obeying The Rule of Silence.
Let’s run bgb ($ wine bgb.exe), secondary-click the window, open first.gb and check out the results!
And that’s it! From code to binary that the Game Boy recognizes, built on MacOS. A world of 8-bit possibilities awaits! A more complete version of this example is available at GBDev.
Simplified GBDK Examples - Repository containing self-contained examples on GBDK concepts. If you’d like to see the printf("Hello, world!"); of the Game Boy world, look no further!
flappybird-gameboy - Reading the source code of other projects is a good way to get started with development in any environment. Flappy Bird is a simple enough game to make for a good first look into GB development in C using GBDK!
SameBoy - An active, open-source emulator written in C with a focus on MacOS support. With its debugging features, it has the potential to become the go-to emulator for development purposes on Mac!
Without realizing it, I uploaded this post on the on the 29th anniversary of the Game Boy’s Japanese release date! Since I was not aware of the Game Boy’s Japanese release date, there was a $\frac{1}{365} = 0.0027%$ chance of this happening! However, taking into account the time-zone difference, I actually uploaded this post at around 7:30AM on the 22nd, Japan time. Oh well, pretty cool in any case!